이전 DFREML에서는 A의 분산비를 고정하고, B의 분산비를 찾고, 다시 B의 분산비를 고정하고 A의 분산비를 찾는 것을 계속 반복했다. Simplex method에서는 A와 B의 분산비를 동시에 수정해서 빠르게 우도함수를 최대화하는 A와 B의 분산비를 찾는다. 찾는 순서는 다음과 같다.
Reflection 후에 Expansion, 채택, Contraction 또는 Shrink 한다. 무슨 말인지 하나씩 보자.
먼저 A와 B의 분산비 하나를 고른다. 여기서는 12.1과 3.8을 골랐다. 그리고 3.8을 고정하고 12.1을 바꾸어 13.1로 하자. 즉 13.1과 3.8이다. 이제 12.1을 고정하고 3.8을 4.3으로 바꾸어 보자. 즉 12.1과 4.3이다. 이 세 개의 분산비 조합으로 시작을 한다.

이제 이들의 L4를 구해 보자. L4를 구하는 방법은 이전 글에서 설명한 R코드를 이용한다. L4를 구하고 L4에 대해서 내림차순으로 정렬한다.

3번이 제일 안 좋은 L4 결과 값을 보였으니 이걸 교체해야 한다. 이걸 Reflection이라고 부른다. 3번을 제외한 1번과 2번의 A와 B 값을 평균한다.
> theta_1 = c(12.1, 3.8)
> theta_2 = c(13.1, 3.8)
> theta_3 = c(12.1, 4.3)
>
> # reflection
> theta_m = (theta_2 + theta_1) / 2
> theta_m
[1] 12.6 3.8이제 다음 공식으로 4번째 A와 B 값을 구한다. r은 1로 한다.

> r = 1
>
> theta_4 = theta_m + r * (theta_m - theta_3)
> theta_4
[1] 13.1 3.3이 13.1과 3.3을 이용하여 L4를 구하고 다시 L4를 기준으로 내림차순 정렬한다.

4번 세트가 가장 좋은 L4 결과를 보였다.

그림으로 설명하면 r_w가 worst일 때 평균 g (centroid)를 구하고 reflection 한다.
이렇게 reflection 해서 구한 세트가 가장 좋은 결과를 보이면 Expansion 한다.

그림으로 설명하면 reflection 한 값이 best이면 확장한다는 뜻이다.
expansion 공식은 다음과 같다. E는 2로 한다.

> # theta_4가 가장 좋은 값이므로 expansion step
> E = 2
>
> theta_5 = theta_m + E * (theta_4 - theta_m)
> theta_5
[1] 13.6 2.8위에서 가장 안 좋은 세트인 1번 세트를 제외하고 5번 세트를 넣어, L4를 구하고 내림차순 정렬한다.

이것이 하나의 iteration이다. reflection한 후에 평가를 해서 expansion 했다.
이제 다음 iteration을 시작한다. reflection. 2번 세트를 제외하고 5와 4번 세트를 평균하고 새로운 세트를 구한다.
> # Begin next iteration
> # reflection
> theta_m = (theta_5 + theta_4) / 2
> theta_m
[1] 13.35 3.05
>
> theta_6 = theta_m + r * (theta_m - theta_2)
> theta_6
[1] 13.6 2.32번 세트를 제외하고, 6번 세트를 넣어 L4를 구하고, 내림차순으로 정렬한다.

6번 세트의 L4 값이 가장 낮은 값을 보였다. 이때는 expansion이 아니라 contraction을 한다.

그림으로 설명하면 reflection 한 값이 Worst가 되었으므로 centroid와 worst 값의 중간으로 간다.
contraction 공식은 다음과 같으며 c = 0.5이다.

> # theta_6가 중간 값과 최악의 값 사이에 있으므로 outside contraction step
> c = 0.5
>
> theta_7 = theta_m + c * (theta_6 - theta_m)
> theta_7
[1] 13.475 2.6757번 세트를 이용하여 L4를 구하고 내림차순으로 정렬한다.

두 번째 iteration을 마쳤다.
새로운 iteration을 시작한다.
> # Begin next iteration
> # reflection
> theta_m = (theta_5 + theta_7) / 2
> theta_m
[1] 13.5375 2.7375
> theta_8 = theta_m + r * (theta_m - theta_4)
> theta_8
[1] 13.975 2.1758번 세트를 넣어, L4를 구하고 내림차순으로 정렬한다.

8번 세트의 L4값이 5번 세트, 7번 세트 및 4번 세트의 L4 보다 작은 값이 나왔다. inside contraction을 한다. inside contraction은 다음과 같이 한다.
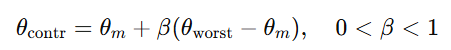
inside contraction이 실패할 경우 즉, 계속해서 새로운 L4값이 최악의 경우보다 낮을 경우 Shrink 한다.

그림으로 설명하면 reflection (r_R) 해도 worst, contraction (r_C) 해도 worst 이면, Worst(r_W)와 Second(r_G)를 best(r_B) 로 당긴다.
여기서는 실패했다고 가정하고 7번 세트와 8번 세트를 Shrink 한다.
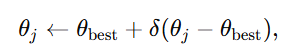
여기서 델타는 0.5로 한다. best는 5번 세트이다. 그래서 새로운 7번 세트와 8번 세트는 다음과 같다.
> # theta_8이 최악의 값보다 작으므로 shrink step
> d = 0.5
> theta_7n = theta_5 + d * (theta_7 - theta_5)
> theta_7n
[1] 13.5375 2.7375
> theta_8n = theta_5 + d * (theta_8 - theta_5)
> theta_8n
[1] 13.7875 2.4875
이와 같은 방식으로 L4를 구해서 비교하고, 새로운 임의효과 A와 B의 분산비를 구하는 과정을 반복한다. 세 점이 같아지면 끝난다. Neder and Mead(1965)가 제시한 reflection, expansion and contraction 상수는 데이터셋에 맞게 수정할 수 있다. 이전의 설명과 마찬가지로 local maximum 일 수 있으므로, global maximum에 도달했다고 생각이 들 때까지, 새로운 starting point로 반복해 봐야 한다. 그리고 simplex method는 추정해야 할 parameter의 수가 많을 경우 잘 동작하지 않는다.
참고)
반사점 위치에 따른 다음 수행 단계
| best보다도 좋음 | Expansion |
| best와 second-best 사이 | 채택 |
| second-best와 worst 사이 | Outside contraction |
| worst보다도 나쁨 | Inside contraction (→ 실패 시 shrink) |