Likelihood는 각 사건이 일어날 확률을 모두 곱한 것이다.
예를 들어 사람의 체중을 측정하였을 때 사람의 체중은 정규분포를 따르므로 평균과 분산이 알려져 있는 집단에서 60kg이 나올 확률은 정규 분포의 probability density function에 60kg을 넣으면 된다.
체중을 60, 65, 70 이렇게 관측하였을 때 MLE로 평균과 분산을 추정한다는 것은 60의 확률, 65의 확률, 70의 확률을 구해서 곱한다는 것이다. 이 확률에는 우리가 추정해야 할 미지의 평균과 분산이 포함되어 있을 것이다.
이렇게 각각의 확률을 구해서 곱한 것을 Likelihood라고 한다. Maximum Likelihood Estimation이라는 것은 어떤 평균과 분산을 취할 때 이 Likelihood가 최대(또는 최소)가 될 것인가라는 문제를 푸는 것이다. 즉 우리가 평균과 분산은 모르지만 어떤 집단에서 체중을 관측하였다. 이러한 관측을 할 수 있는 확률(이게 Likelihood)이 최대가 되게 하는 평균과 분산을 찾는 것이 maximun likelihood estimation이다.
MLE를 하기 위해서는 그러므로 분포 즉 확률 밀도 함수(probability density function)를 알고 있어야 한다. 많은 관측치가 정규 분포하는 집단에서 관측되므로 정규 분포하는 집단에서 관측치를 구하였을 경우 평균과 분산에 대하여 MLE하는 것을 설명한다.
각각의 확률을 곱할 경우 매우 다루기 힘든 형태가 되는데, 어차피 최대, 최소와 관련된 문제는 미분을 해서 0로 놓는데 로그를 한 후에 미분을 해서 0으로 놓아도 같은 결과가 나온다. 그래서 각각의 확률을 곱하고(likelihood), 로그를 먼저 한 후(log)에 미분(maximum)을 한다.



결론적으로 MLE로 구한 평균이나 산술평균이나 같고, 분산도 마찬가지이다. 하지만 log-likelihood는 다양한 분야에서 사용되므로 알아 두는게 좋다.
다변량 정규분포의 Maximum Likelihood Estimation
위에서 체중에 대해서 얘기하였는데, 체중과 키를 동시에 다룬다면 다변량 정규 분포를 다루는 것이다.
우선 다변량 정규분포 함수(probability density function)가 왜 그렇게 생겼는지 알아 보고, 다변량 정규분포 함수의 Likelihood를 구하고, 평균과 분산에 대한 Maximum Likelihood Estimation을 할 것이다.
다변량 정규분포 함수를 유도(derivation of multivariate normal distribution)해 보자. 다변량 표준 정규 분포를 유도하고, 선형 변환을 이용하여 다변량 정규분포 함수를 유도한다.
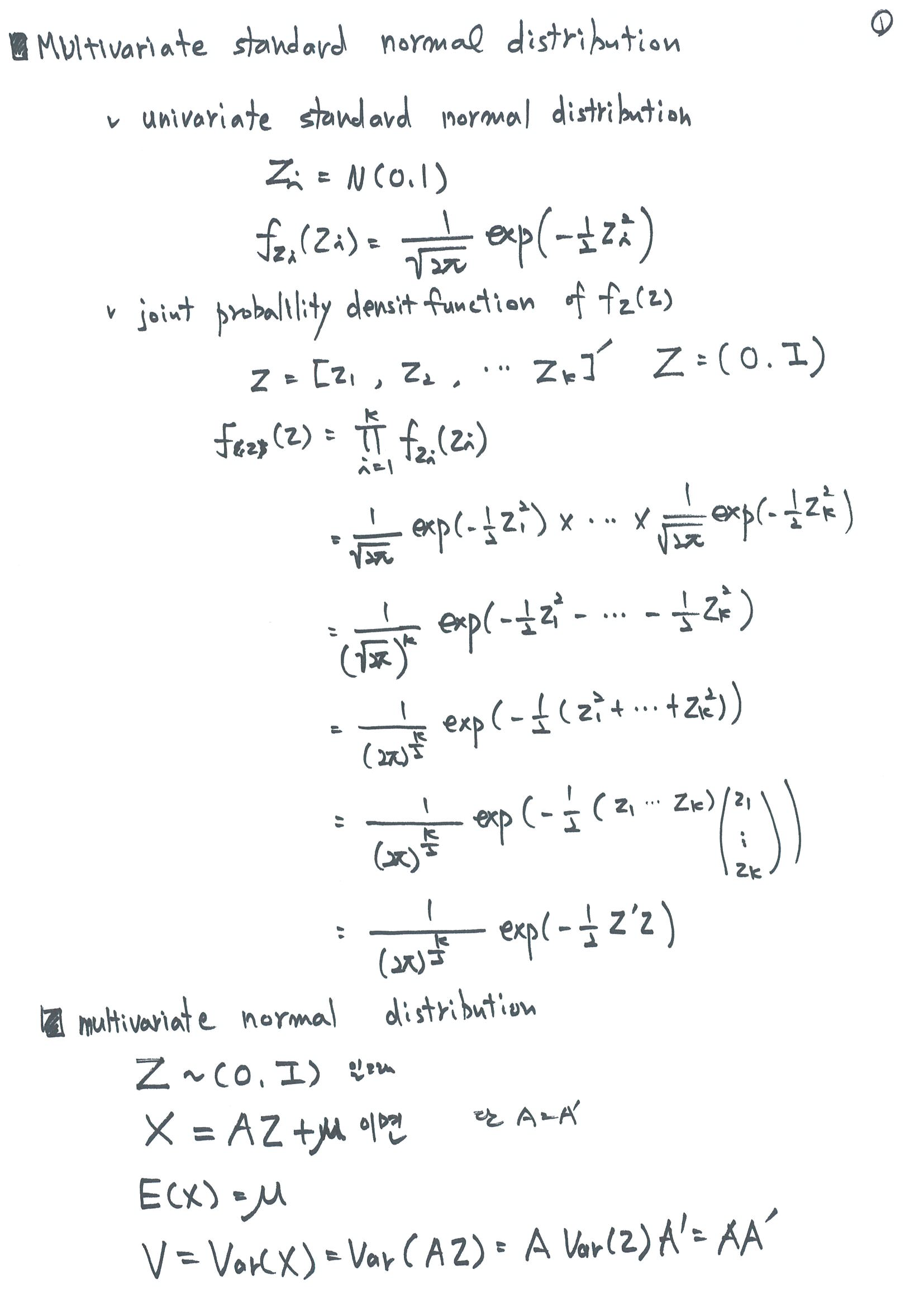
다변량 정규 분포의 likelihood를 구하고, 로그를 취하고, 최대화하는 mean과 variance를 구해 보자.
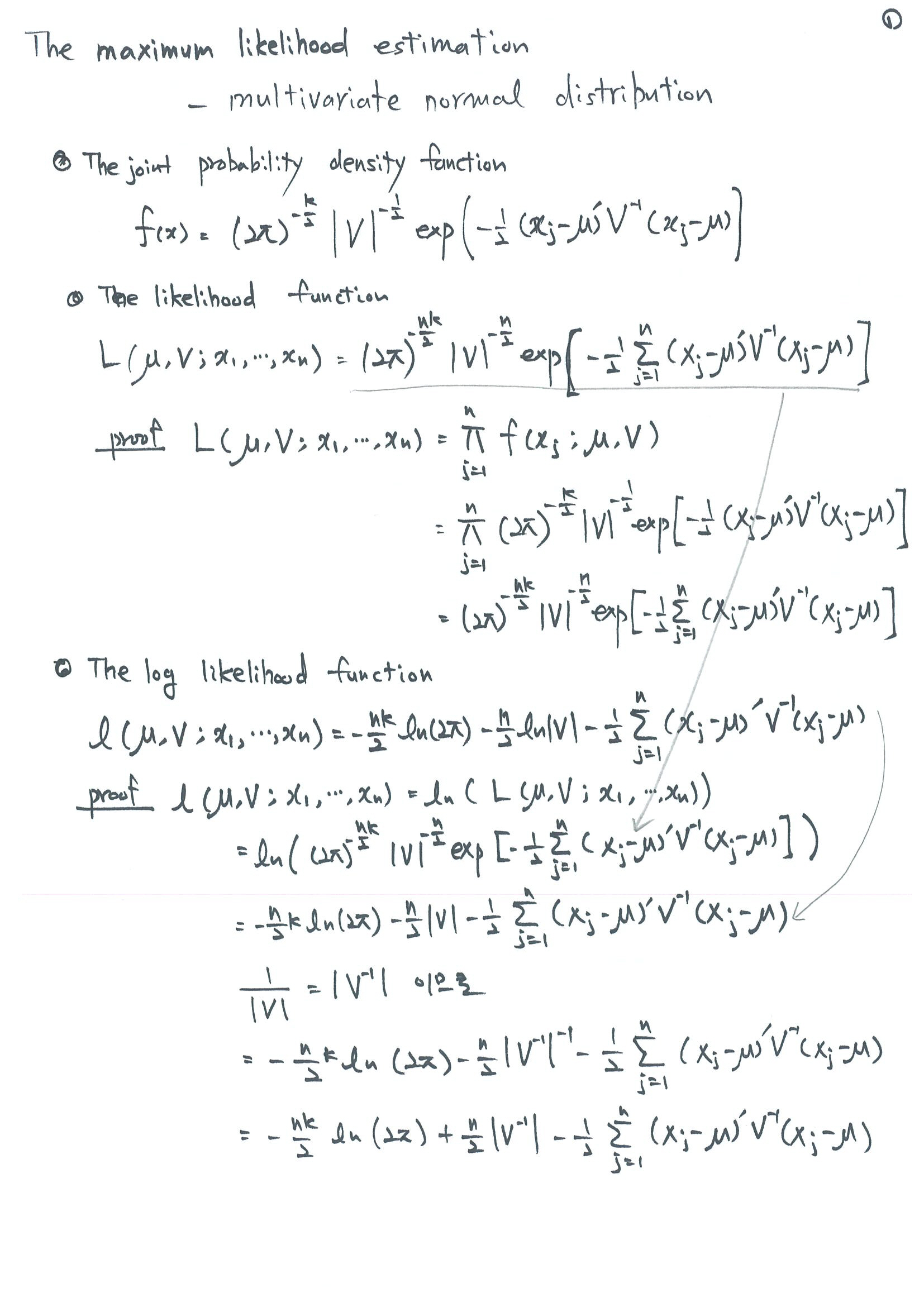


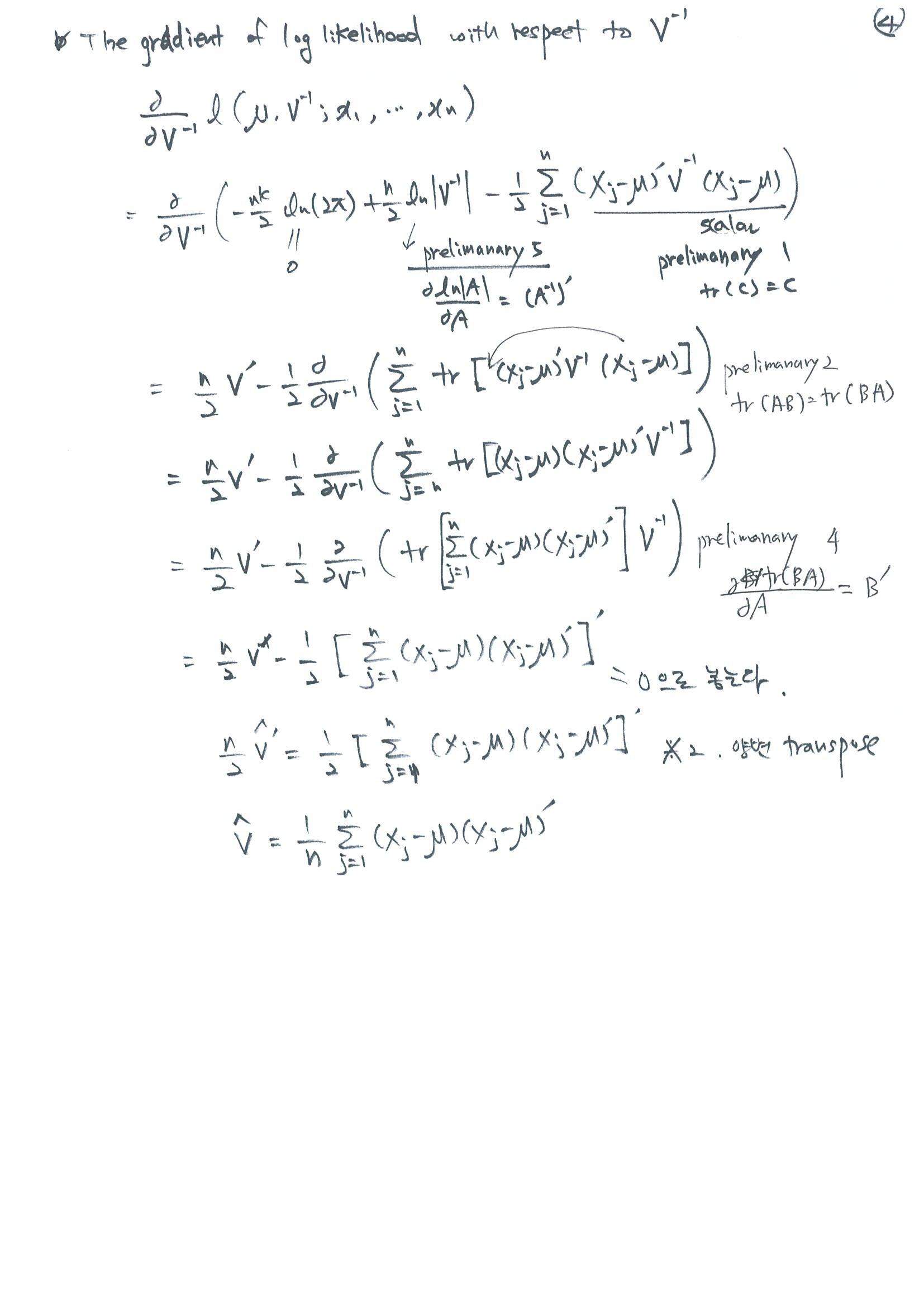
행렬을 미분할 때 필요한 몇 가지 공식과 합성 함수의 미분법도 같이 써 주었다.
분산 성분 추정(Estimation of variance component)을 위해서 사용하는 REML(Restricted or Residual Maximum Likelihood)를 이해하기 위한 기초자료로 Maximum Likelihood Estimation을 정리하였다.
'Animal Breeding > Animal Breeding Etc' 카테고리의 다른 글
| 다변량 정규 분포 함수의 유도 (0) | 2025.07.18 |
|---|---|
| 표본 데이터와 확률 변수 (0) | 2025.07.16 |
| Derivation of Mixed Model Equation(MME) (0) | 2025.07.02 |
| Pedigree Completeness Index (0) | 2015.11.24 |
| unix join command를 이용한 renumbering (0) | 2012.02.12 |